本篇主要介绍基于Chrome的webdriver进行爬虫的基本方法,整理下来以备遗忘。
上个周师姐布置任务让我爬取知网的作者知网节,本来以为看起来挺好爬的,但知网还是有些坑,之后详细介绍。下面就让我们从零开始吧。
一、环境配置
我们主要用到的工具有python中的selenium和chrome,以及需要驱动chrome的插件webdriver。
下面是来自百度关于selenium的介绍。
从图中我们可以看到,利用selenium我们可以模拟用户的浏览器行为,从而获取到我们需要的网页内容,因为能模拟用户行为,所以利用selenium进行爬虫自然可以一定程度上避免被网站反爬虫拦截,但也有不好的一面,比如爬取的速度相对来说会慢一些。
1. 安装selenium
1 | pip install selenium |
当然我们也可以新建一个conda环境,再进行安装selenium,这里简单复习一下创建并激活conda环境的命令:
1 | #创建新环境 |
2. 安装基于浏览器的webdriver
selenium支持多种浏览器,比如chrome和firefox等等,这里我选用了chrome:下载地址
注意选择和浏览器版本对应的chromedriver。
- win
直接将解压后的chromedriver直接拖进chrome的安装目录,然后配置环境变量。 - mac
将解压后的chromedriver拖进/usr/local/bin/即可。 - linxu
将解压后的chromedriver拷贝进/usr/bin目录,之后在代码中声明路径即可。
另外以上,默认已装好Chrome,如果没有,请自行百度。
二、代码编写
1. 简单使用
1 | from selenium import webdriver |
接下来让我们在百度的搜索框中输入些什么进行搜索看看。
既然要输入,那我们首先需要找到在哪个位置进行输入,因此我们需要简单定个位,打开百度页面的源代码看一下输入框在哪。
我们可以发现原来这个输入框的class = "s_ipt",那我们就先通过class来定位试试吧!
1 | search_input = browser.find_element_by_class_name('s_ipt') |
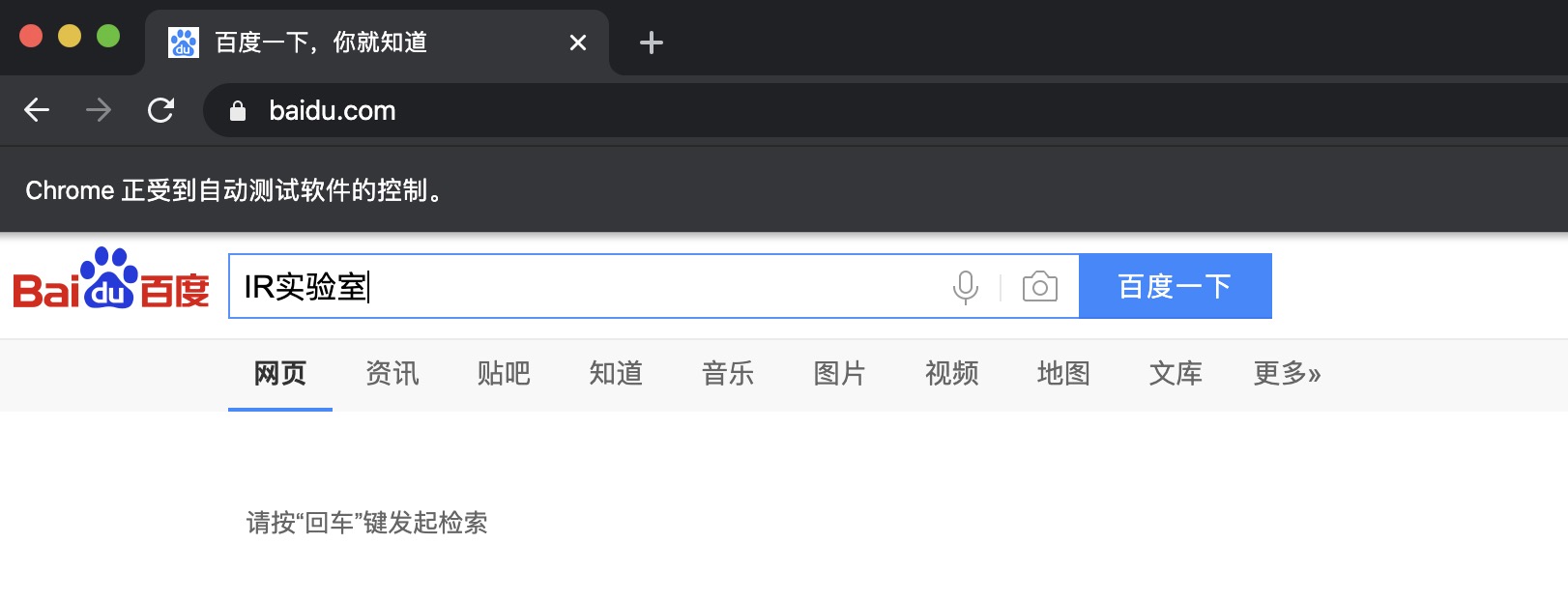
可以看到我们成功的在输入框里输入了搜索内容,下面就让我们点击一下“百度一下”搜索试试吧。
看一下“百度一下”按键的源码是什么: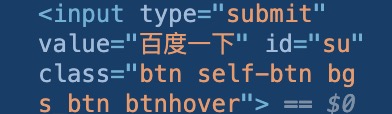
可以发现它的id = "su",那我们就通过id来定位它吧!
1 | browser.find_element_by_id('su').click() |
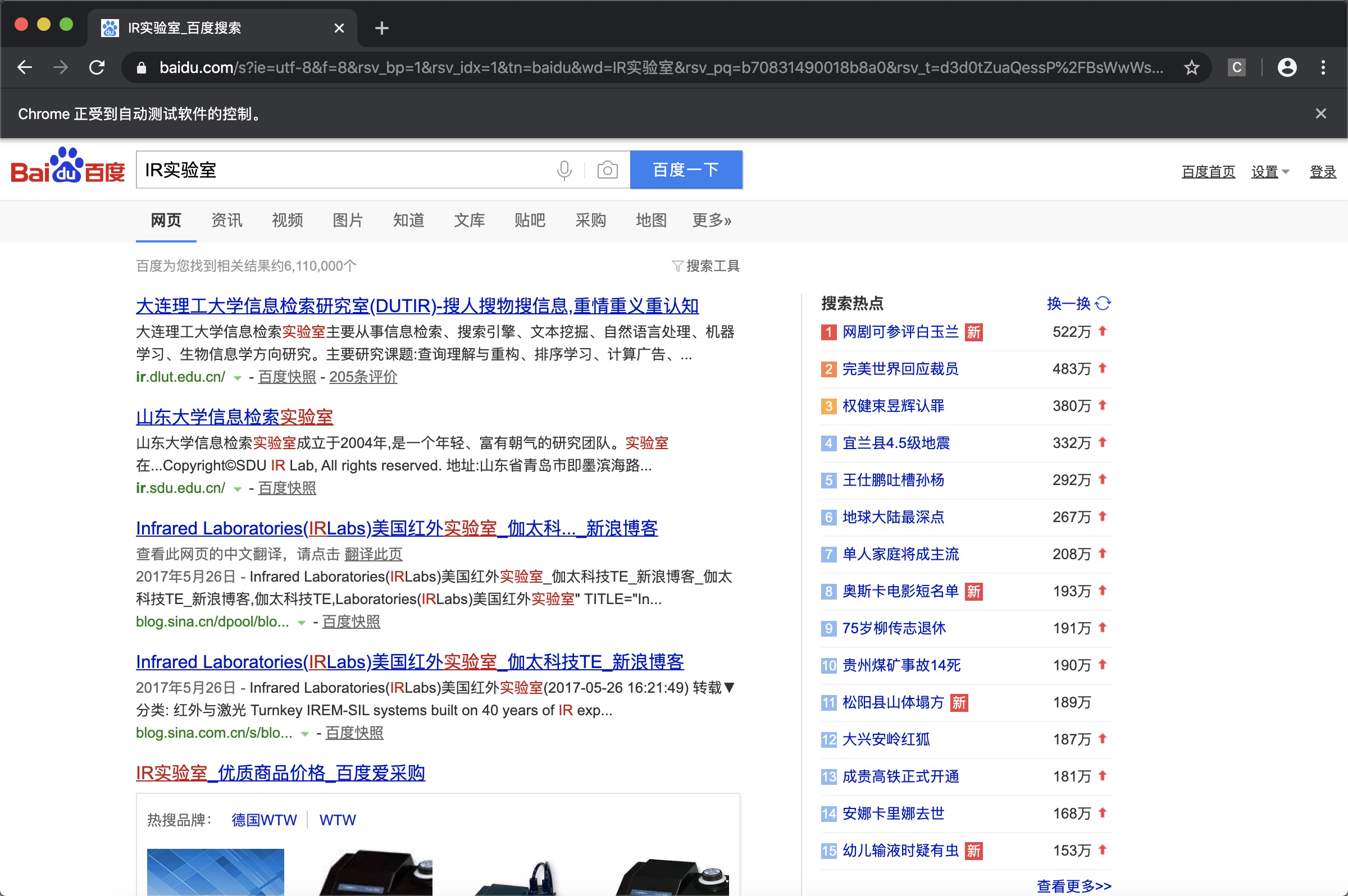
除了通过点击“百度一下”按钮,我们通常搜索的时候一般是直接按回车键的,那在这里可不可以模拟回车键呢?
1 | from selenium.webdriver.common.keys import Keys |
2. 定位问题
模拟浏览器行为无非就是模拟鼠标和键盘来操作html中的这些元素,那首要的任务就是元素定位问题了。
在selenium中提供了很多种方法可以进行元素定位,下面一一介绍。
(1) id定位
find_element_by_id()
例如上面的例子我们定位了“百度一下”按钮:browser.find_element_by_id('su')
(2) name定位
find_element_by_name()
1 | <input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off"> |
比如这是百度搜索框的源码,我们可以通过name这样定位:browser.find_element_by_name('wd')
(3) class定位
find_element_by_class_name()
同样地定位搜索框:browser.find_element_by_class_name('s_ipt')
(4) tag定位
find_element_by_tag_name()
每一个元素本质就是一个tag,但是HTML页面的tag重复性很厉害,一般很少用这个定位。
例子:browser.find_element_by_tag_name('input')
(5) link定位
find_element_by_link_text() 可以用来定义文本链接。
1 | <a href="http://news.baidu.com" target="_blank" class="mnav">新闻</a> |
我们可以通过这些文本内容打开链接:browser.find_element_by_link_text('新闻').click()
也可以通过部分文本链接进行定位,也就是partial定位:find_element_by_partial_link_text()
例子:browser.find_element_by_partial_link_text('hao').click()
(6) xpath定位
它又分为绝对路径定位和相对路径定位,但我觉得没人喜欢/html/*/*/这样从头写路径,经常使用的也就是相对路径定位。find_element_by_xpath('//标签[@属性名=属性值]') 属性名可以是id、name、class或者其他可唯一标识该标签的元素。
比如上面定位百度搜索框的可以改写为:browser.find_element_by_xpath('//input[@class="s_ipt"]').send_keys('IR 实验室')//代表当前页面的某个路径下,input代表元素标签名,不指定标签可以用*代替。
既然xpath都支持路径了,那层级,也就是在某个标签之下的元素也可以通过它定位了。
比如,有个div标签的class=’helloworld’,然后在这个标签的里面有一个a标签,我们想要定位这个a标签就可以这么写:browser.find_element_by_xpath('//div[@class="helloworld"]/a')
更强大的是这个方法还支持通过逻辑运算符进行定位。
比如find_element_by_xpath("//input[@id='a' and @class='su']/span/input")
(7) CSS定位
find_element_by_css_selector()
通过class定位
比如在百度搜索框输入要搜索的内容:browser.find_element_by_css_selector(".s_ipt").send_keys('hello world')
通过id定位
例子:browser.find_element_by_css_selector("#kw").send_keys('hello world')
通过标签名定位 (很少用)
例子:browser.find_element_by_css_selector("input")
通过标签属性定位
例子:browser.find_element_by_css_selector('[autocomplete="off"]').send_keys('helloworld')
属性值的引号可加可不加。
通过标签父子关系定位
find_element_by_css_selector("parent>child")
例子:browser.find_element_by_css_selector("span>input").send_keys("IR 实验室")
组合定位
例子:browser.find_element_by_css_selector("span>input#kw").send_keys("IR 实验室")
同样的,可以将属性值、id、class、父子关系等结合起来组合定位,这样可以提高定位的准确性。
(8) 通过By定位
By定位元素是统一调用find_element()的方法。find_element()方法只用于定位元素,它有两个参数,第一个是定位的类型,由By提供;第二个参数是定位的具体方式。
使用By之前需要先导入By类:
1 | from selenium.webdriver.common.by import By |
实例:browser.find_element(By.ID,'kw').send_keys("IR 实验室")
定位的类型包括:By.ID, By.NAME, By.CLASS_NAME, By.TAG_NAME, By.LINK_TEXT, By.PARTIAL_LINK_TEXT, By.XPATH, By.CSS_SELECTOR
3. 出现定位不到元素的问题
你以为掌握了以上这些定位方法就没有问题了吗,当时看完教程的我也是这么想的,不就是爬取知网作者知网节嘛,当我把一切都准备好,也打开了准备爬取的页面,准备开心的开始爬的时候呢,却报错了…找不到该元素,我明明在chrome里可以看到的啊,我定位的方法也没有错啊,怎么会定位失败呢?
原来现在很多页面除了页面源代码之外还有很多框架源代码,而我想要爬取的内容就存在于这些框架源代码中,那这些框架源代码都在哪呢?
看到这些iframe标签了嘛,没错它们都在这里面。
frame标签有frameset、frame、iframe三种,frameset跟其他普通标签没有区别,不会影响到正常的定位,而frame与iframe对selenium定位而言是一样的,selenium有一组方法对frame进行操作。
所以我们如果想要这里面的内容就需要切换frame,之后才能定位到这些框架里的元素,那么怎么进行切换呢?
我们用到的函数是switch_to.frame()可以传入id、name、index以及selenium的WebElement对象。
1 | from selenium import webdriver |
但是我们看到知网这个作者知网节界面不只一个框架,但这些框架都是同级的,所以我们爬完一个框架之后需要切回主文档以再切入下一个框架。driver.switch_to.default_content()
那如果碰到一个框架里面又嵌套着框架怎么办呢?比如:
1 | <html> |
我们先从主文档一层一层的切到frame2
1 | driver.switch_to.frame("frame1") |
现在我们从frame2怎么切换到frame1呢?
1 | driver.switch_to.parent_frame() # 如果当前已是主文档,则无效果 |
有了这个方法,相当于后退作用,我们就可以随意的在frame之间切换了。
三、其他常用函数补充
切换标签页:
1 | window = self.browser.window_handles # 获得当前窗口句柄集合(列表类型) |
控制浏览器前进、后退、刷新
1 | browser.forward() |
关闭浏览器
1 | browser.quit() |
写在最后
如果你想获取完整的爬取知网作者知网节的代码:
1 | git clone https://github.com/aestheticisma/spider_cnki |